혼자한다.
아니다. 지피티와 함께 한다.
*****
이번 구글 검색이 앞선 포스트의 네이버 뉴스 검색과 가장 큰 차이점은 다음과 같다.
네이버는 뉴스 검색을 했을 때 뉴스 게시 날짜를 정확하게 알 수가 없다. 검색일로부터 몇시간 전 또는 몇일 전으로만 나온다.
실제 기사의 게재시점을 정확하게 추적할 수 없었는데,
구글 뉴스 검색에서 이 부분을 해소했다.
이제 정확하게 뉴스 게시 날짜를 알 수 있게 됐다.
그리고 코랩에서 작업함으로써 결과물 저장도 로컬 PC가 아니라 구글 드라이브로 가능하게 되서
자료 공유에도 보다 손 쉬워졌다.
********
코드 설명은 아래 참고
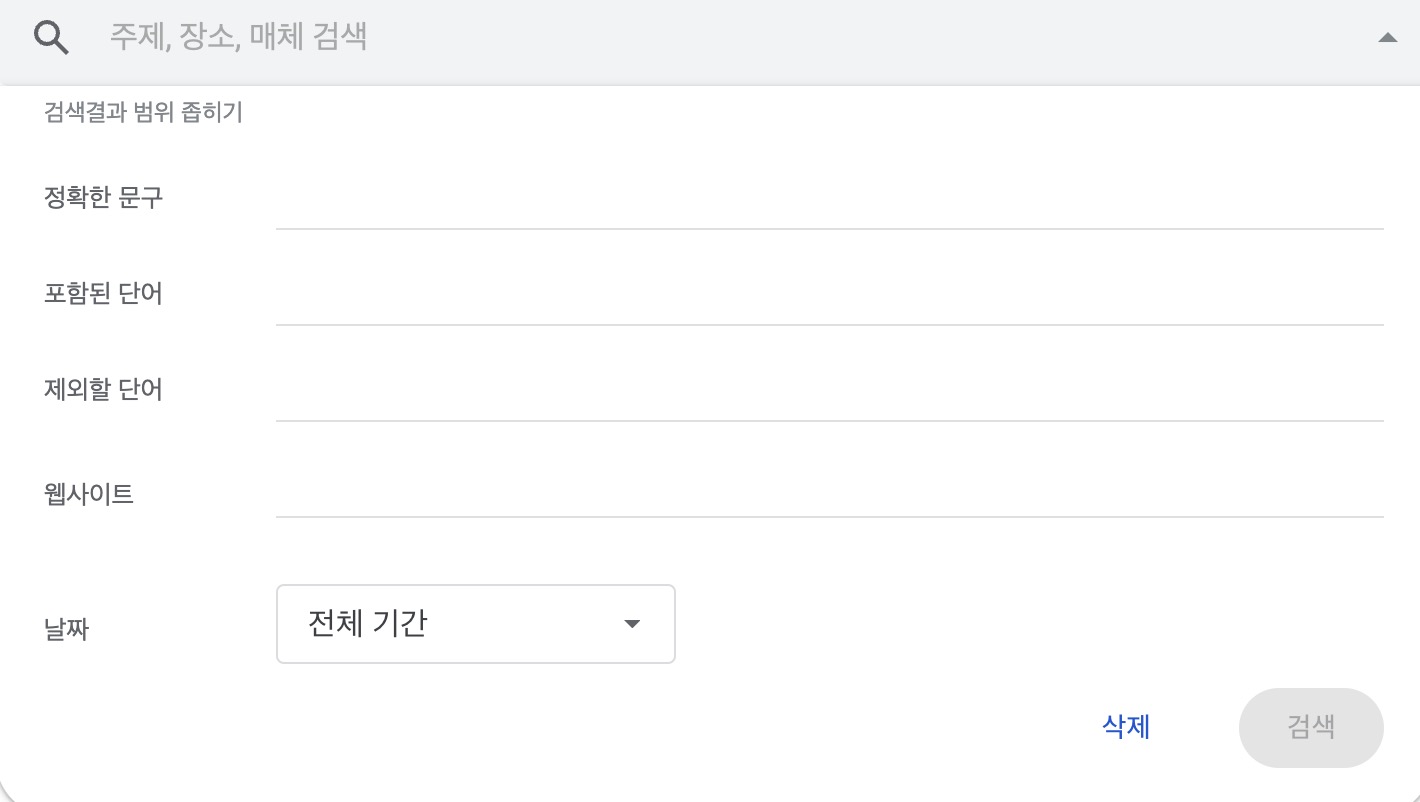
구글 뉴스 검색에 고급 기능이 있다.
'정확한 문구' 와 날짜 기능 입력 기능이다.
아래와 같다.
여기서 [정확한 문구]에 '키워드'를 입력하고
[날짜]는 원하는대로 조정하면 된다.
코드 전문은 아래다.
여기서 날짜를 조정하는 것은 아래 base url 중간에 보면, '7d'라고 되어 있는 부분을 '1d'로 바꾸면
하루짜리로 바뀐다.
base_url = 'https://news.google.com/search?q=%22{}%22%20when%3A7d&hl=ko&gl=KR&ceid=KR%3Ako'
from google.colab import drive
import requests
from bs4 import BeautifulSoup
from datetime import datetime, timedelta
import pandas as pd
# Mount Google Drive
drive.mount('/content/drive')
def fetch_news(keyword, url, news_data, max_articles=100):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.find_all('a', class_='JtKRv')[:max_articles]
times = soup.find_all('time', class_='hvbAAd')[:max_articles]
publishers = soup.find_all('div', class_='vr1PYe')[:max_articles]
if not articles:
print("No news found for keyword:", keyword)
return
for article, time, publisher in zip(articles, times if times else [None]*len(articles), publishers if publishers else [None]*len(articles)):
title = article.get_text(strip=True)
link = 'https://news.google.com' + article['href'][1:]
utc_time = datetime.strptime(time['datetime'], '%Y-%m-%dT%H:%M:%SZ') if time else datetime.now()
kst_time = utc_time + timedelta(hours=9)
formatted_time = kst_time.strftime('%Y-%m-%d')
publisher_name = publisher.get_text(strip=True) if publisher else 'Unknown Publisher'
news_data.append([keyword, title, publisher_name, link, formatted_time])
print(f"Keyword: {keyword} | Title: {title} | Publisher: {publisher_name} | Link: {link} | Date: {formatted_time}")
except requests.exceptions.RequestException as e:
print(f"Error fetching news for keyword {keyword}: {e}")
def save_news_to_excel(news_data):
execution_time = datetime.now().strftime("%Y%m%d_%H%M%S")
df = pd.DataFrame(news_data, columns=['Keyword', 'Title', 'Publisher', 'Link', 'Posted At'])
excel_path = f'/content/drive/My Drive/news_feed_{execution_time}.xlsx'
df.to_excel(excel_path, index=False)
print(f"Excel file saved to {excel_path}")
if __name__ == "__main__":
news_data = []
keywords = []
while True:
keyword = input("Enter a keyword for news search (type 'end' to execute): ")
if keyword.lower() == 'end':
break
keywords.append(keyword)
base_url = 'https://news.google.com/search?q=%22{}%22%20when%3A7d&hl=ko&gl=KR&ceid=KR%3Ako'
for keyword in keywords:
url = base_url.format(keyword)
fetch_news(keyword, url, news_data)
save_news_to_excel(news_data)'python' 카테고리의 다른 글
| 엑셀 파일 통합: VBA 매크로 vs 파이썬 - 어떤 방법이 더 좋을까? (0) | 2024.06.20 |
|---|---|
| 웹 스크래핑 마스터하기: 종합적인 Python 튜토리얼 (0) | 2024.06.01 |
| [혼자하는 파이썬] 파이썬으로 무료 쇼츠 만들기 (1) | 2024.03.29 |
| [혼자하는 파이썬] 파이썬으로 mp3 음원 만들기 (1) | 2024.03.29 |
| [혼자하는 파이썬] 파이썬으로 네이버 뉴스 검색 마스터: 검색어와 기간 설정하기 (0) | 2024.03.08 |